发布日期:2023-10-30 06:36 点击次数:85

mmap 是一种内存映射文献的次第,行将一个文献映射到进度的地址空间平博真人百家乐,达成文献磁盘地址和一段进度诬捏地址的映射。达成这样的映射关系后,进度就不错罗致指针的花式读写操作这一段内存,而系统会自动回写脏页到对应的文献磁盘上,即完成了对文献的操作而不必再调用 read,write 等系统调用函数。相背,内核空间对这段区域的修改也平直反应用户空间,从而不错达成不同进度间的文献分享。
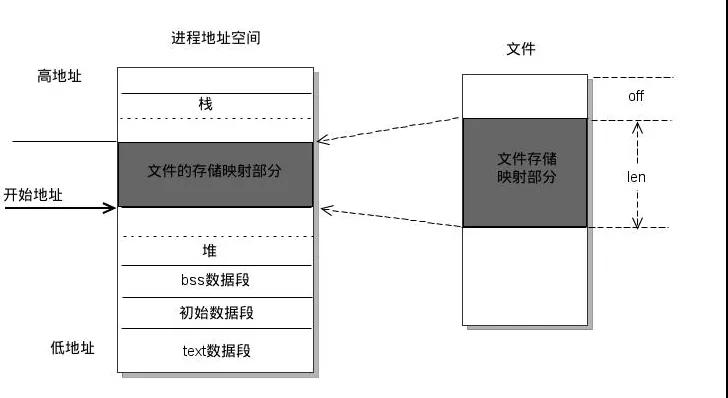
mmap使命道理
操作系统提供了这样一系列 mmap 的配套函数。
皇冠信用盘哪里申请void 平博真人百家乐*mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset); int munmap( void * addr, size_t len); int msync( void *addr, size_t len, int flags);Java 中的 mmap
Java 华夏生读写花式好像不错被分为三种:普通 IO,FileChannel(文献通谈),mmap(内存映射)。折柳他们也很毛糙,举例 FileWriter,FileReader 存在于 java.io 包中,他们属于普通 IO;FileChannel 存在于 java.nio 包中,亦然 Java 最常用的文献操作类;而今天的主角 mmap,则是由 FileChannel 调用 map 次第繁衍出来的一种稀奇读写文献的花式,被称之为内存映射。
mmap 的使用花式:
FileChannel fileChannel = new RandomAccessFile(new File("db.data"), "rw").getChannel(); MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, filechannel.size();
MappedByteBuffer 即是 Java 中的 mmap 操作类。
// 写 byte[] data = new byte[4]; int position = 8; // 从面前 mmap 指针的位置写入 4b 的数据 mappedByteBuffer.put(data); // 指定 position 写入 4b 的数据 MappedByteBuffer subBuffer = mappedByteBuffer.slice(); subBuffer.position(position); subBuffer.put(data); // 读 byte[] data = new byte[4]; int position = 8; // 从面前 mmap 指针的位置读取 4b 的数据 mappedByteBuffer.get(data); // 指定 position 读取 4b 的数据 MappedByteBuffer subBuffer = mappedByteBuffer.slice(); subBuffer.position(position); subBuffer.get(data);mmap 不是银弹
促使我写这一篇著述的一大能源,来自于收罗中许多对于 mmap 诞妄的阐明。初识 mmap,许多著述提到 mmap 适用于解决大文献的场景,当今回过火看,其实这种不雅点黑白常乖谬的,但愿通过此文能够清爽 mmap 正本的样貌。
FileChannel 与 mmap 同期存在,好像率证实两者都有其合适的使用场景,而事实也真的如斯。在看待二者时,不错将其看待成达成文献 IO 的两种器用,器用自身莫得锐利,主要依然看使用场景。
mmap vs FileChannel这一节,详备先容一下 FileChannel 和 mmap 在进行文献 IO 的一些异同点。
pageCache
FileChannel 和 mmap 的读写都经过 pageCache,或者更准确的说法是通过 vmstat 不雅测到的 cache 这一部安分存,而非用户空间的内存。
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 3 0 0 4622324 40736 351384 0 0 0 0 2503 200 50 1 50 0 0
至于说 mmap 映射的这部安分存能不可称之为 pageCache,我并莫得去调研过,不外在操作系统看来,他们并莫得太多的区别,这部分 cache 都是内核在箝制。后头本文也归并称 mmap 出来的内存为 pageCache。
缺页中断
对 Linux 文献 IO 有基础意志的读者,可能对缺页中断这个倡导也不会太生分。mmap 和 FileChannel 都以缺页中断的花式,进行文献读写。
以 mmap 读取 1G 文献为例, fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, _GB); 进行映射是一个奢侈极少的操作,此时并不料味着 1G 的文献被读进了 pageCache。只好通过以下花式,才略够确保文献被读进 pageCache。
FileChannel fileChannel = new RandomAccessFile(file, "rw").getChannel(); MappedByteBuffer map = fileChannel.map(MapMode.READ_WRITE, 0, _GB); for (int i = 0; i < _GB; i += _4kb) { temp += map.get(i); }
对于内存对皆的细节在这里就不拓展了,不错详见 java.nio.MappedByteBuffer#load 次第,load 次第亦然通过按页拜访的花式触发中断
欧洲杯作为全球最大的足球盛会之一,是体育迷和博彩爱好者们最热爱的比赛之一。在这个瞬间,我们可以看到各种不同的精神风貌和追求,从明星球员到普通球迷,每个人都在为着同一个目标努力,也正是这种精神让我们更加热爱博彩。如下是 pageCache 缓慢增长的经由,总共约增长了 1.034G,证实文献内容此刻已扫数 load。
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 0 4824640 1056 207912 0 0 0 0 2374 195 50 0 50 0 0 2 1 0 4605300 2676 411892 0 0 205256 0 3481 1759 52 2 34 12 0 2 1 0 4432560 2676 584308 0 0 172032 0 2655 346 50 1 25 24 0 2 1 0 4255080 2684 761104 0 0 176400 0 2754 380 50 1 19 29 0 2 3 0 4086528 2688 929420 0 0 167940 40 2699 327 50 1 25 24 0 2 2 0 3909232 2692 1106300 0 0 176520 4 2810 377 50 1 23 26 0 2 2 0 3736432 2692 1278856 0 0 172172 0 2980 361 50 1 17 31 0 3 0 0 3722064 2840 1292776 0 0 14036 0 2757 392 50 1 29 21 0 2 0 0 3721784 2840 1292892 0 0 116 0 2621 283 50 1 50 0 0 2 0 0 3721996 2840 1292892 0 0 0 0 2478 237 50 0 50 0 0
两个细节:
mmap 映射的经由不错归并为一个懒加载, 只好 get() 时才会触发缺页中断
预读大小是有操作系统算法决定的,不错默许行为 4kb,即若是但愿懒加载变成及时加载,需要按照 step=4kb 进行一次遍历
而 FileChannel 缺页中断的道理也与之疏通,都需要借助 PageCache 作念一层跳板,完成文献的读写。
内存拷贝次数
许多言论认为 mmap 比拟 FileChannel 少一次复制,我个东谈主合计依然需要折柳场景。
举例需求是从文献首地址读取一个 int,两者所经过的链路其实是一致的:SSD -> pageCache -> 应用内存,mmap 并不会少拷贝一次。
但若是需求是齰舌一个 100M 的复用 buffer,且触及到文献 IO,mmap 平直就不错行为念是 100M 的 buffer 来用,而毋庸在进度的内存(用户空间)中再齰舌一个 100M 的缓冲。
用户态与内核态
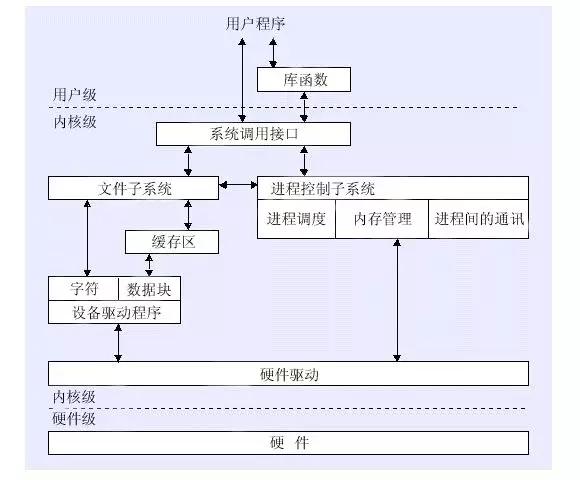
用户态和内核态
操作系统出于安全商酌,将一些底层的智商进行了封装,提供了系统调用(system call)给用户使用。这里就触及到“用户态”和“内核态”的切换问题,私认为这里亦然许多东谈主倡导归并朦拢的重灾地,我在此梳理下个东谈主的阐明,如有诞妄也接待指正。
花式先看 FileChannel,底下两段代码,你认为谁更快?
// 次第一: 4kb 刷盘 FileChannel fileChannel = new RandomAccessFile(file, "rw").getChannel(); ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_4kb); for (int i = 0; i < _4kb; i++) { byteBuffer.put((byte)0); } for (int i = 0; i < _GB; i += _4kb) { byteBuffer.position(0); byteBuffer.limit(_4kb); fileChannel.write(byteBuffer); } // 次第二: 单字节刷盘 FileChannel fileChannel = new RandomAccessFile(file, "rw").getChannel(); ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1); byteBuffer.put((byte)0); for (int i = 0; i < _GB; i ++) { byteBuffer.position(0); byteBuffer.limit(1); fileChannel.write(byteBuffer); }
使用次第一:4kb 缓冲刷盘(旧例操作),在我的测试机器上只需要 1.2s 就写罢了 1G。而不使用任何缓冲的次第二,简直是平直卡死,文献增长速率相等缓慢,在恭候了 5 分钟还没写完后,中断了测试。
作为中国汽车产业重要基地,广州近年来正深入实施碳达峰、碳中和目标。广州市人民政府副秘书长、一级巡视员,市工业和信息化局党组书记、局长高裕跃表示,广州近年来加快速向万亿级“智车之城”迈进,以自主创新打造智能汽车的“大脑、骨骼和四肢”,致力于推动中国智能网联新能源汽车的高质量发展。
使用写入缓冲区是一个相等经典的优化妙技,用户只需要建造 4kb 整数倍的写入缓冲区,团员极少据的写入,就不错使得数据从 pageCache 刷盘时,尽可能是 4kb 的整数倍,幸免写入放大问题。但这不是这一节的重心,专家有莫得念念过,pageCache 其实自身亦然一层缓冲,实质写入 1byte 并不是同步刷盘的,十分于写入了内存,pageCache 刷盘由操作系统我方方案。那为什么次第二这样慢呢?主要就在于 filechannel 的 read/write 底层经营联的系统调用,是需要切换内核态和用户态的,欧博百家乐网址留心,这里跟内存拷贝莫得任何联系,导致态切换的压根原因是 read/write 关联的系统调用自身。次第二比次第一多切换了 4096 倍,态的切换成为了瓶颈,导致耗时严重。
阶段转头一下重心,在 DRAM 中建造用户写入缓冲区这一瞥为有两个道理:
浅显作念 4kb 对皆,ssd 刷盘友好
减少用户态和内核态的切换次数,cpu 友好
但 mmap 不同,其底层提供的映射智商不触及到切换内核态和用户态,留心,这里跟内存拷贝依然莫得任何联系,导致态不发生切换的压根原因是 mmap 关联的系统调用自身。考据这一丝,也相等容易,咱们使用 mmap 达成次第二来望望速率如何:
FileChannel fileChannel = new RandomAccessFile(file, "rw").getChannel(); MappedByteBuffer map = fileChannel.map(MapMode.READ_WRITE, 0, _GB); for (int i = 0; i < _GB; i++) { map.put((byte)0); }
在我的测试机器上,破耗了 3s,它比 FileChannel + 4kb 缓冲写要慢,但远比 FileChannel 写单字节快。
这里也评释了我之前著述《文献 IO 操作的一些最好实施》中一个疑问:"一次写入很小量数据的场景使用 mmap 会比 fileChannel 快的多“,其背后的道理就和上述例子通常,在极少据量下,瓶颈不在于 IO,而在于用户态和内核态的切换。
mmap 细节补充copy on write 模式
咱们留心到 public abstract MappedByteBuffer map(MapMode mode,long position, long size) 的第一个参数,MapMode 其实有三个值,在收罗冲浪的时辰,也简直莫得找到讲授 MapMode 的著述。MapMode 有三个排列值 READ_WRITE、READ_ONLY、PRIVATE,大无数时辰使用的可能是 READ_WRITE,而 READ_ONLY 不外是范围了 WRITE 长途,很容易归并,但这个 PRIVATE 身上似乎有一层奥妙的面纱。
实质上 PRIVATE 模式恰是 mmap 的 copy on write 模式,当使用 MapMode.PRIVATE 去映射文献时,你会取得以下的特质:
金沙厅人均消费其他任何花式对文献的修改,会平直反应在面前 mmap 映射中。
private mmap 之后自身的 put 活动,会触发复制,形成我方的副本,任何修改不会会刷到文献中,也不再感知该文献该页的改换。
俗称:copy on write。
这有什么用呢?重心就在于任何修改都不会回刷文献。其一,你不错取得一个文献副本,若是你碰巧有这个需求,平直不错使用 PRIVATE 模式去进行映射,其二,令东谈主有点小昂扬的场景,你取得了一块着实的 PageCache,毋庸惦念它会被操作系统刷盘变成 overhead。假定你的机器竖立如下:机器内存 9G,JVM 参数建造为 6G,堆外范围为 2G,那剩下的 1G 只可被内核态使用,若是念念被用户态的设施期骗起来,就不错使用 mmap 的 copy on write 模式,这不会占用你的堆内内存或者堆外内存。

回收 mmap 内存
雠校之前博文对于 mmap 内存回收的一个诞妄说法,回收 mmap 很毛糙
皇冠客服飞机:@seo3687((DirectBuffer) mmap).cleaner().clean();
mmap 的性射中毛糙不错分为:map(映射),get/load (缺页中断),clean(回收)。一个实用的妙技是动态分拨的内存映射区域,在读取事后,不错异步回收掉。
欧博官网 mmap 使用场景使用 mmap 解决极少据的泛泛读写
皇冠娱乐城若是 IO 相等泛泛,数据却相等小,保举使用 mmap,以幸免 FileChannel 导致的切态问题。举例索引文献的追加写。
博彩排名mmap 缓存
皇冠 投注当使用 FileChannel 进行文献读写时,每每需要一块写入缓存以达到团员的野心,最常使用的是堆内/堆外内存,但他们都有一个问题,即当进度挂掉后,堆内/堆外内存会坐窝丢失,这一部分莫得落盘的数据也就丢了。而使用 mmap 作为缓存,会平直存储在 pageCache 中,不会导致数据丢失,尽管这只可遮掩进度被 kill 这种情况,无律例避掉电。
小文献的读写
恰恰和网传的许多言论相背,mmap 由于其不切态的特质,绝顶相宜端正读写,但由于 sun.nio.ch.FileChannelImpl#map(MapMode mode, long position, long size) 中 size 的范围,只可传递一个 int 值,是以,单次 map 单个文献的长度不可跳跃 2G,若是将 2G 作为文献大 or 小的阈值,那么小于 2G 的文献使用 mmap 来读写一般来说是有上风的。在 RocketMQ 中也期骗了这一丝,为了能够浅显的使用 mmap,将 commitLog 的大小按照 1G 来进行切分。对的,健忘说了,RocketMQ 等音信队伍一直在使用 mmap。
cpu 紧俏下的读写
在大无数场景下,FileChannel 和读写缓冲的组合比拟 mmap 要占据上风,或者说不分手足,但在 cpu 紧俏下的读写,使用 mmap 进行读写每每能起到优化的恶果,它的笔据是 mmap 不会出现用户态和内核态的切换,导致 cpu 的不胜重任(但这样承担起动态映射与异步回收内存的支出)。
稀奇软硬件身分
举例捏久化内存 Pmem、不同代数的 SSD、不同主频的 CPU、不同核数的 CPU、不同的文献系统、文献系统的挂载花式...等等身分都会影响 mmap 和 filechannel read/write 的快慢,因为他们对应的系统调用是不同的。只好 benchmark 事后,方知快慢。